Reference-Less Evaluation of Machine Translation: Navigating Through the Resource-Scarce Scenarios
Reference-Less Evaluation of Machine Translation: Navigating Through the Resource-Scarce Scenarios
Abstract
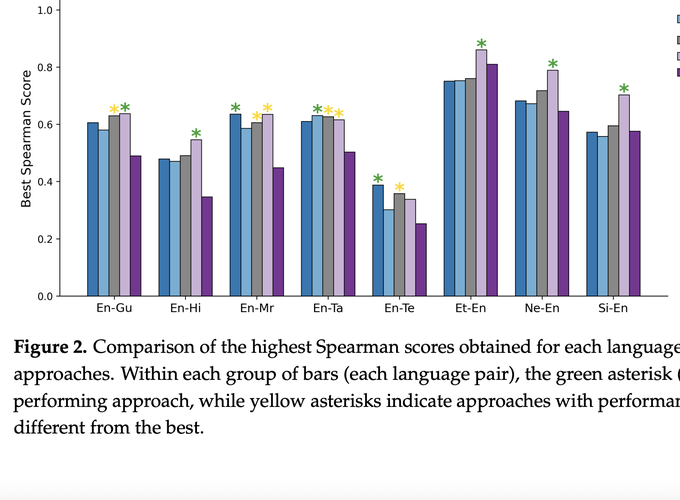
Reference-less evaluation of machine translation, or Quality Estimation (QE), is vital for low-resource language pairs where high-quality references are often unavailable. In this study, we investigate segment-level QE methods comparing encoder-based models such as MonoTransQuest, CometKiwi, and xCOMET with various decoder-based methods (Tower+, ALOPE, and other instruction-fine-tuned language models). Our work primarily focused on utilizing eight low-resource language pairs, involving both English on the source side and the target side of the translation. Results indicate that while fine-tuned encoder-based models remain strong performers across most low-resource language pairs, decoder-based Large Language Models (LLMs) show clear improvements when adapted through instruction tuning. Importantly, the ALOPE framework further enhances LLM performance beyond standard fine-tuning, demonstrating its effectiveness in narrowing the gap with encoder-based approaches and highlighting its potential as a viable strategy for low-resource QE. In addition, our experiments demonstrates that with adaptation techniques such as LoRA (Low Rank Adapters) and quantization, decoder-based QE models can be trained with competitive GPU memory efficiency, though they generally require substantially more disk space than encoder-based models. Our findings highlight the effectiveness of encoder-based models for low-resource QE and suggest that advances in cross-lingual modeling will be key to improving LLM-based QE in the future.