Abstract
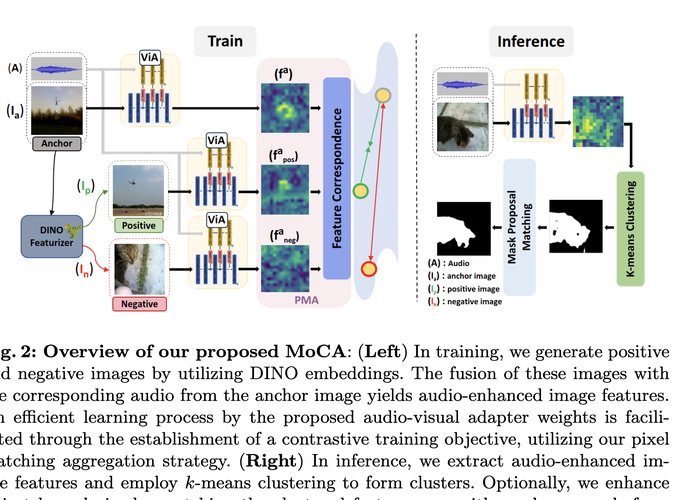
Audio-Visual Segmentation (AVS) aims to identify, at the pixel level, the object in a visual scene that produces a given sound. Current AVS methods rely on costly fine-grained annotations of mask-audio pairs, making them impractical for scalability. To address this, we propose the Modality Correspondence Alignment (MoCA) framework, which seamlessly integrates off-the-shelf foundation models like DINO, SAM, and ImageBind. Our approach leverages existing knowledge within these models and optimizes their joint usage for multimodal associations. Our approach relies on estimating positive and negative image pairs in the feature space. For pixel-level association, we introduce an audio-visual adapter and a novel pixel matching aggregation strategy within the image-level contrastive learning framework. This allows for a flexible connection between object appearance and audio signal at the pixel level, with tolerance to imaging variations such as translation and rotation. Extensive experiments on the AVSBench (single and multi-object splits) and AVSS datasets demonstrate that MoCA outperforms unsupervised baseline approaches and some supervised counterparts, particularly in complex scenarios with multiple auditory objects. In terms of mIoU, MoCA achieves a substantial improvement over baselines in both the AVSBench (S4: +17.24%, MS3: +67.64%) and AVSS (+19.23%) audio-visual segmentation challenges.